 Products
Products




Ready to get started?
No matter where you are on your CMS journey, we're here to help. Want more info or to see Glide Publishing Platform in action? We got you.
Book a demoWhy better tagging suggestions come from combining semantic similarity, editorial history, and taxonomy structure
An article about a topic needs much more than just its most basic singular tag if it is to thrive within a publishing chain of sites, apps, newsletters and wherever else it may be sent and seen.
A story about an Apple product will need much more information than just "tech company" - it will do better if it includes other ways to slice and dice what the story is about, perhaps such as "smartphone", "iPhone", "App Store", or whatever else the article is about.
Being able to extract or suggest the most relevant tags to an editor or systems is genuinely useful and time-saving, and helps bring content to more attention than any single tag ever could.
AI has of course sprung up to aid the process of categorising content more efficiently - but just throwing content into an AI and expecting it to work miracles can be a sobering moment: without a host of other signals around what a piece of content is, it will often do worse than a human in adding the right tags.
It's missing the all important thing: context.
Let's look at how a site and a CMS actually moves and manages content, the best source of truth for how a site works and how people actually think. Looking at the video game Sea of Thieves - and you should, it's great - an article about the sea-borne adventure game will need more than simply a tag of the game's name. Depending on the publication’s taxonomy, editors may also add a bunch of related forms of categorisation, such as the development house, the publisher, the genre and a platform - Rare, Xbox Studios, Adventure, and PC/Xbox/PlayStation (in this case all three).
Those choices decide where the story appears across the site: in search, archives, topic pages, recommendations, related content, and image workflows. Quickly it has become vastly more complicated than just adding a 'Sea of Thieves' tag and quickly starts to reflect not just how people can connect the dots, but how a site is structured to suit the needs of the publication. Tagging is much less about spotting mentions and a glorified search, than it is about applying the publication’s classification rules consistently.
Semantic search, which tries to derive the context and meaning behind a search rather than just surface the limited "I can see this set of words..." answer of basic tagging, is useful because of that drive to establish connections and intent. Search for "open-world RPGs" and it may surface stories about titles like Skyrim or Breath of the Wild without needing the name of the games themselves, because they are within the meaning of the search, which may also return a guide on "what is an open-world RPG?".
On the other hand, for suggesting and applying tags to a piece of content in a way that is useful to an editor or writer, the useful question is narrower and much more referenced to the title and specific practices of the publication: which approved taxonomy terms match this article, based on the taxonomy and on how editors handled similar stories before?
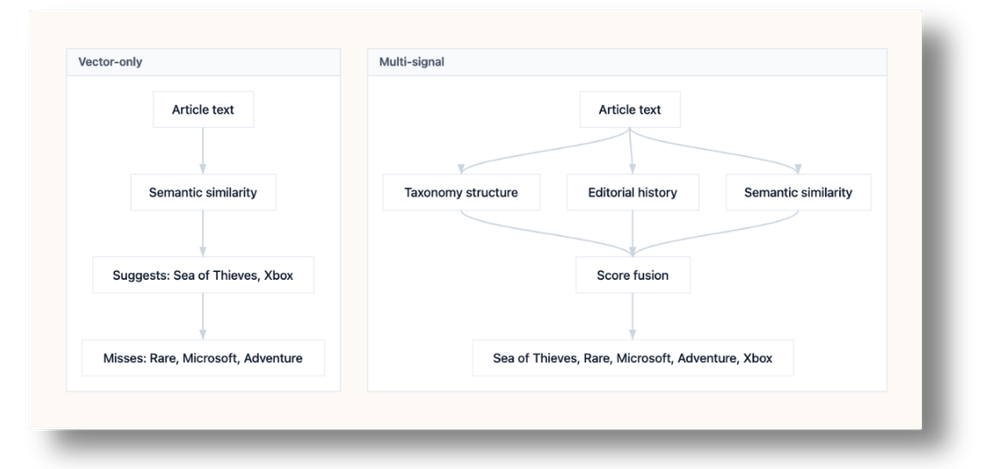
A model may recognise that a story is about Sea of Thieves, and it may even suggest Xbox. But without access to your taxonomy and tagging history, it will not reliably know that your editors usually apply Rare, Microsoft, Adventure, and Xbox alongside it, or that those terms belong to different parts of a structured taxonomy.
When leaning on semantic-only tagging, failures are predictable and editors notice them quickly: editorial decisions look wrong, connections between topics and content aren't made, and suggestions drift toward terms that are close in meaning but wrong for the job. You don't want your Apple story to end up in the food and groceries section, for example.
A newsroom writing about the game Cyberpunk 2077 may consistently add the tag of the developer and publisher CD Projekt Red, but a semantic model will not automatically know that this pairing is both a part of your editorial practice, and an important piece of information to populate matching "developer" and "publisher" topic pages pages on the front-end, and also to be able to show related content alongside the actual Cyberpunk 2077 piece. Here, the model sees related language but not the house style or publication intent.
The same problem shows up with taxonomy relationships that matter editorially but are not obvious from language alone. Sea of Thieves may belong under Adventure in your taxonomy because of how your publication classifies games, but a semantic-only approach may not infer that relationship reliably.
One other problem is when suggestions look plausible but wrong. If two entities sit in the same broad area of meaning in the wider world, the system may suggest something that looks reasonable at first glance but is still wrong - for example, in the case of Sea of Thieves, it may suggest a plausible genre of Strategy - but your site has chosen to put it elsewhere under Adventure. Eventually, editors will stop trusting the assistant when too many suggestions look plausible at first glance but fail under editorial review.
Vector-only tagging relies on semantic similarity alone. Multi-signal tagging adds taxonomy structure and editorial history before ranking suggestions.
A stronger system starts with the terms already in the CMS and ranks them using several kinds of evidence: explicit entity matches, similar articles, past tag usage, and taxonomy links. For editors, the important point is simple: suggestions are not invented. They come from the existing taxonomy and are ordered by how well they fit this article and the way the publication has tagged similar work before. Keeping that established hierarchy is the key.
The system can use entity matches, vector similarity, similar articles, past tag co-occurrence, and taxonomy links to score each candidate term offered to an editor.
Semantic understanding
In general, embeddings provide a useful baseline for identifying what an article is broadly about, and which existing taxonomy terms are conceptually related. That angle is important, but it should not be treated as the whole decision as it doesn't give the full picture.
Learning editorial rules from your own data
Every mature publication has tagging rules that were never properly written down. They live in old articles, editor habits, and conventions passed around the team.
A multi-signal system can learn some of those patterns by analysing historical content. Across thousands of articles, it might observe that Cyberpunk 2077 is often tagged with CD Projekt Red, The Witcher 3 - another game by the same studio - and the relevant platform tags for what device the game can be played on; that game news articles commonly include platform and genre tags; or that certain studios usually carry their parent publisher and franchise tags even when those are not mentioned in the headline.
These associations come from your editors’ past decisions, not from an LLM guessing based on the open internet. When a new article arrives, the system can use that history as evidence: in similar cases, editors tended to apply these tags, so they may be relevant here too.
Context and hierarchy awareness
Taxonomies are structured systems, not flat lists, as we explored in why hierarchical taxonomies outclass free-form tagging. Studios can belong to publishers, genres can sit under broader categories, and platforms are a different kind of term from developers or franchises.
A multi-signal system can use those relationships directly. If a suggested entity belongs to a known part of the taxonomy, the system can use that context when ranking related terms, rather than treating every tag as an isolated label.
Corroboration, not guesswork
The strongest suggestions are usually supported by more than one kind of evidence. If a term appears in similar articles, sits near a matched entity in the taxonomy, and has been used by editors in comparable cases, it should rank higher. If the evidence is thin, it should fall down the list or disappear.
When a new article enters the CMS, the system scores the known taxonomy terms and entities already available to that publication. Terms rise when several signals support them, and drop when the match is only vague.
The result is a shorter review list, with fewer loose associations and more terms that match how the publication has handled similar stories before.
Take a real article from a gaming publication: “CD Projekt Red announce extensive layoffs.” Editors assigned eight taxonomy terms to this piece. The vector-only baseline found two of them: CD Projekt Red and Cyberpunk 2077.
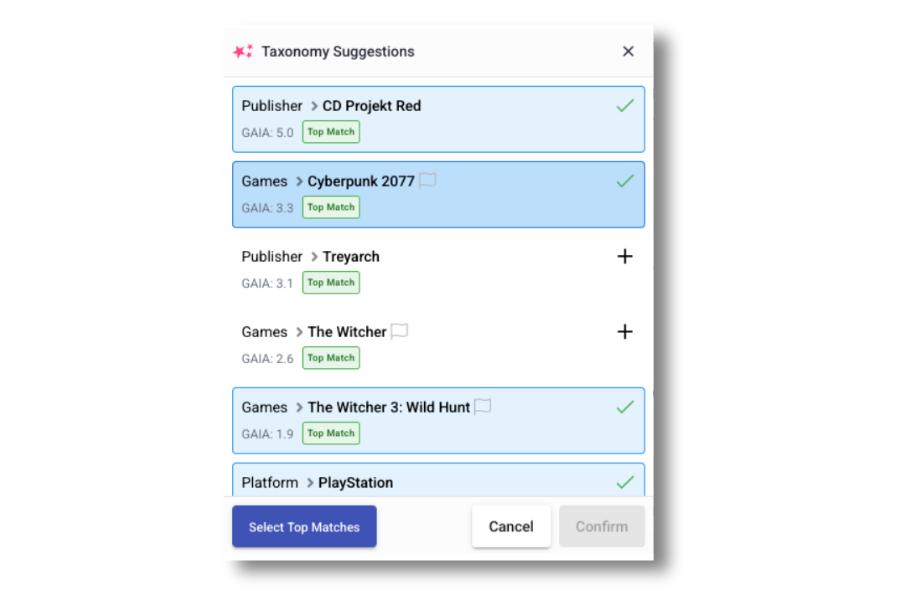
Taxonomy suggestions inside Glide CMS, surfaced for editor review before publishing.
The multi-signal system found all eight in the same test case. Every suggestion still came from known taxonomy terms, but the ranking had more evidence to work with. CD Projekt Red and Cyberpunk 2077 were supported by explicit matching, vector similarity, similar articles, and historical co-occurrence, while the remaining tags came from similarity and historical patterns.
For the editor, the practical change is huge: instead of starting with a loose semantic match, they start with a list that better reflects how the publication already classifies this kind of article.
Bad tags do not stay inside the tagging interface. They affect archive quality, related-content modules, site search, image retrieval, recommendations, and the SEO strength of topic landing pages.
They also create a small but constant editorial tax. When first-pass suggestions are better, editors spend less time correcting obvious gaps, teams apply taxonomy terms more consistently, and new joiners have an easier path into the conventions that experienced editors may never have written down.
Measured results
We evaluated the system against 1,000 real articles from a gaming publication, sampled from 27,577 qualifying articles. Each article was sent to the suggestion engine with its headline and body text, then the output was compared against the taxonomy terms editors had actually applied.
The vector-only baseline used the same article text and the same pool of existing taxonomy terms, but ranked suggestions by embedding similarity alone. It did not use historical tag co-occurrence or taxonomy relationships.
We measured recall, meaning how many editor-applied tags the system found, and precision, meaning how many suggestions were actually correct. The applicable "F1 score", which is a machine learning metric used to evaluate a classification model's accuracy, combines the two into a single metric.
| Metric | Vector-only | Multi-signal |
|---|---|---|
| Recall | 20% | 97% |
| Precision | 7% | 47% |
| F1 score (a combined measure of recall and precision) | 10% | 63% |
This is a publication-specific benchmark, not a universal claim. The results cannot be read as a promise that every taxonomy will behave the same way. But the sample is large enough to show how the system performs across a real editorial archive, rather than a hand-picked demo set.
The articles carried between three and 15 editor-applied taxonomy terms each, with a median of seven. With the default top-15 configuration, the system returned an average of 6.7 correct suggestions per article and reached 100% recall on 786 of the 1,000 articles. That makes the CD Projekt Red example useful as an illustration, not a one-off success case.
A precision score of 44.8% means editors still have some weak suggestions to dismiss. But in an assistive tagging workflow, the bigger cost is often the missing tag: the editor has to remember it, search for it, and add it manually.
That is why recall matters. In the same top-15 setup, the vector-only baseline returned only 1.7 correct suggestions on average, while the multi-signal system returned 6.7.
The recall vs precision tradeoff
The system’s aggressiveness can be configured per title. Publishers can tune the balance between recall and precision depending on how their editors prefer to work.
| Configuration | Recall | Precision | F1 |
|---|---|---|---|
| Conservative (top 5) | 57% | 78% | 66% |
| Balanced (top 10) | 93% | 66% | 78% |
| Default (top 15) | 97% | 47% | 63% |
| High recall (top 20) | 98% | 35% | 52% |
The balanced configuration has the highest F1 Score, which makes it the cleanest statistical choice. Editorial workflows may favour a different setting.
In many CMS workflows, recall matters more than precision. A missing obvious tag forces the editor to think of it, search for it, and add it manually. Most importantly in that chain is the catalyst - they need to know it is missing. An extra suggestion is easier to reject. For that reason, some publishers may still prefer the default or high-recall setting, even with a lower precision score.
Data requirements. Semantic matching can work from day one, provided the taxonomy terms and entities have enough useful text attached to them. Pattern learning needs more history. In practice, it becomes more meaningful once there are a few thousand tagged articles, and it improves as the editorial archive grows.
Real-time updates
When an article is published or updated, embeddings and relationship data can be refreshed so future suggestions reflect recent editorial decisions. The exact timing depends on the integration, but updates do not need to wait for occasional manual retraining cycles.
Integration
An API-first design lets suggestions appear inside existing editorial workflows rather than forcing editors into a separate tool. REST APIs and typed SDKs also make the same features available to automated workflows, not only to the CMS interface.
Multi-tenant by design
Each publication's taxonomy, entities, and learned patterns stay isolated. Editorial conventions are title-specific, and they should not leak between publications.
Semantic search helps identify related topics, but editorial tagging depends on a publication or site’s own taxonomy and archive. The strongest suggestions come from terms already in the CMS, ranked against how editors have tagged similar stories before.
Glide CMS uses multi-signal taxonomy suggestions in production today, helping editors review tags that reflect their own content model and editorial conventions.
To see how this works with your content model, request a demo with a Glide product specialist.
No matter where you are on your CMS journey, we're here to help. Want more info or to see Glide Publishing Platform in action? We got you.
Book a demo